
by Lee Gesmer | Jun 9, 2026 | Copyright
On June 2, 2026, the Fifth Circuit heard argument in Emmerich Newspapers, Inc. v. Particle Media, Inc., the first time a federal court of appeals outside the Ninth Circuit has had to decide whether embedding content that lives on someone else’s server infringes the copyright owner’s exclusive right of public display. I took up that question in 2018 (Is In-Line Linking Illegal Now?) and again in 2022, in a post titled “Is ‘Photo Embedding’ Copyright Infringement? It Depends on the Court.” My answer in 2022 was just that: it depends on the court. Emmerich may be the case that changes the answer, and a ruling either way could finally push this issue to the Supreme Court.
A reminder of what the courts are struggling with.
The Copyright Act grants authors the exclusive right “to display the copyrighted work publicly,” and that right has proven remarkably resistant to resolution in the internet context. Courts across the country have been unable to agree on a deceptively simple question: when a website embeds an image that lives on someone else’s server, and that image appears on a visitor’s screen, who has displayed it?
The answer matters enormously for how the web works. Embedding is ubiquitous. News articles embed tweets and Instagram posts. Blogs pull in YouTube videos. Aggregators surface images from across the internet. If embedding counts as a public display by the embedder, vast swaths of ordinary internet activity become potential copyright infringement. If it doesn’t, copyright holders may find themselves powerless to stop third parties from making their images appear on millions of screens without credit, without payment, and without permission.
To see how the law got here, and why Emmerich matters so much, we have to start with the Ninth Circuit’s 2007 landmark decision in Perfect 10, Inc. v. Amazon.com, Inc.
The Perfect 10 “Server Test”
Perfect 10 involved Google Image Search, which pulled full-size images in from third-party sites through inline linking. Did Google violate the image-owners’ right of public display?
The Ninth Circuit found its answer in how the Copyright Act defines three terms: “display,” “copy,” and “fixed.” To “display” a work is to “show a copy” of it. A “copy” is a material object in which the work is “fixed,” and a digital image is fixed when it is stored on a server. The Ninth Circuit reasoned that a party displays a work only when it shows a copy stored on its own server.
That distinction decided the case. Google never stored the images, which remained on the third-party sites that had posted them. All Google sent the user’s browser was a line of HTML, a string of text giving the address where the image lived. Because Google had no copy of the image to show, the court held, it did not display it.
That reasoning became known as the “server test,” and for years it functioned as the safe harbor for the entire embedding ecosystem: if the image sits on someone else’s server, the embedder has not displayed it. The Ninth Circuit doubled down in Hunley v. Instagram, LLC (2023), holding that BuzzFeed and Time did not infringe when they embedded photographers’ Instagram posts in news articles. The court also rejected the argument that the test should be limited to search engines. It applies, the court said, based on the method of display, not the setting in which the display occurs.
The District Courts Revolt
The trouble is that the Ninth Circuit has been alone. Outside it, the server test has met steady resistance, and the most influential rejection came in Goldman v. Breitbart News Network, LLC (2018), a case I discussed here. Justin Goldman photographed Tom Brady on the street in the Hamptons, posted it to Snapchat, and watched it spread to Twitter. Several news outlets embedded the tweet in articles about Brady. None stored the photo. Goldman sued, and under the server test, that should have been the end of the case.
However, Southern District of New York Judge Katherine Forrest disagreed, and her reasoning has framed the debate ever since:
“The Court agrees with plaintiff. The plain language of the Copyright Act, the legislative history undergirding its enactment, and subsequent Supreme Court jurisprudence provide no basis for a rule that allows the physical location or possession of an image to determine who may or may not have “displayed” a work within the meaning of the Copyright Act.”
The statute defines “display” as showing a copy, she explained, not as making and then showing a copy. In her view, the server test reads a reproduction requirement into the display right that Congress never wrote, effectively collapsing one exclusive right into another. She also made a common-sense point that has stuck: copyright liability should not turn on a technical distinction that is invisible to the person actually looking at the image.
The Second Circuit never resolved this issue. It declined interlocutory review, the case settled, and Judge Forrest’s opinion has sat on the books, unreviewed, ever since. Other courts picked up the thread. The Southern District of New York reached the same result in McGucken v. Newsweek (2022) and Nicklen v. Sinclair Broadcasting Group (2021). The Northern District of Texas, in Leader’s Institute v. Jackson (2017), said that to the extent Perfect 10 required possession of a copy before there could be a display, it respectfully disagreed.
A pattern ran through several of these decisions: the courts tried to preserve a carve-out for search engines, suggesting Perfect 10 might still be right in its original setting even if it should not be extended. A group of copyright scholars who later weighed in as amici at the Fifth Circuit had no patience for that move. Congress wrote specific exemptions into the Copyright Act where it wanted them, for libraries, for classrooms, for certain small businesses. Search engines are not on the list. Inventing one by judicial improvisation, they argued, is not statutory interpretation.
What all this produced was a standoff, but not a circuit split. The only appellate law endorsed the server test, while a growing line of trial courts found it wrong, and copyright plaintiffs who could pick their forum increasingly filed outside the Ninth Circuit. As I wrote in 2022, that left website owners with no safe option but to treat embedding as risky everywhere, at least until an appeals court outside the Ninth Circuit finally ruled. Two 2025 cases may have now brought that moment close.
Texas Splits From Itself: UrbanImage
In July 2025, the Western District of Texas rejected the server test in UrbanImage Media Ltd. v. IHeartMedia, Inc. A Denver radio affiliate of IHeartMedia ran an online “in memoriam” article about the musician Chuck E. Weiss and embedded a YouTube video that contained a screengrab of a photograph of Tom Waits owned by UrbanImage.
The photo lived on YouTube’s servers, not IHeartMedia’s, and IHeartMedia moved to dismiss based on the server test. District Court Judge Xavier Rodriguez was not persuaded, and he gave three reasons. First, the server test contradicts the text: “display” means showing a copy, not making and then showing one. Second, the fixation question is closer than Perfect 10 let on, because embedded code causes an image to appear on the screen for more than a transitory duration, which is enough to satisfy the statutory definition of “fixed.” Third, where in Hunley the Ninth Circuit had brushed aside the Supreme Court’s decision in American Broadcasting v. Aereo (2014) as a public-performance case, Judge Rodriguez read Aereo the other way, for the broader proposition that invisible technical distinctions should not decide liability when the user’s experience is identical. He also found that IHeartMedia’s deliberate steps, going to YouTube, copying the embed code, and dropping it into the article, easily met the volitional-conduct requirement for direct infringement. Motion to dismiss denied.
The significance is hard to miss. UrbanImage sits in the Fifth Circuit, and so does Emmerich, the case that produced the opposite result and is now on appeal. The circuit’s own district courts are pointing in opposite directions.
The Case to Watch: Emmerich
Emmerich Newspapers, Inc. v. Particle Media, Inc. is the one to watch, and it is a bigger case than a single misused photograph. Emmerich Newspapers publishes local news across Mississippi. Particle Media runs NewsBreak, a news-aggregation app whose crawler scraped thousands of Emmerich’s articles. For some, NewsBreak copied the full text onto its own platform. For the others, the ‘framed-view’ articles, NewsBreak used a WebView to display Emmerich’s content from Emmerich’s own website, inside a window wrapped in the NewsBreak interface and ads.
The full-view articles were never going to survive. Particle copied and stored that content, which is exactly what the server test treats as infringing. The framed-view articles are the interesting part. Particle argued that because it never stored or served that content, it never displayed it. It was acting like a browser, pointing users to material Emmerich was hosting and transmitting itself.
The district court agreed. Judge Tom Lee acknowledged the district courts that have gone the other way, but found the Ninth Circuit’s reasoning more persuasive, and noted the obvious: there is no Fifth Circuit precedent, and the Ninth Circuit is still the only court of appeals to have ruled on this issue. He identified what Patry on Copyright describes as the “fatal flaw” in the opposing view, that the embedder does not transmit a display of the work but only tells the browser where to find it. He added a point specific to framing: even in framed-view, Emmerich’s content stayed on Emmerich’s servers, so the party actually displaying it was Emmerich, not Particle.
Emmerich appealed, and the case has drawn a crowd. Professor Mark Lemley and other copyright scholars filed an amicus brief supporting Particle. Their core argument is that the entity that publicly displays a work online is the one whose server transmits it. Embedding is not transmission, it is direction. The embedder tells a browser where to look; the host server decides whether and what to send, and keeps ultimate control, since it can refuse the request, delete the file, or block embedding altogether. Treat embedding as direct infringement, they warn, and you turn millions of ordinary users and publishers into infringers overnight. The Fifth Circuit heard argument in early June 2026, and a decision is now awaited.
What’s at Stake
The stakes run in both directions, which may be why this has stayed unresolved for so long. If the server test is wrong, photographers and other creators get real recourse against sites that put their work on the page without permission, payment, or credit. The reader’s experience is the same whether the image is stored locally or pulled in from elsewhere, so why should that hidden difference decide who is liable?
But if the server test goes, the exposure for the ordinary web is enormous. Embedding is not a fringe practice; it is how the web is built. Every article that embeds a tweet, every blog that pulls in a video, every aggregator that surfaces third-party content becomes a potential direct infringer, and statutory damages reach $150,000 per work for willful infringement. A handful of embedded images could sink a small publisher. There is also a real question of where responsibility belongs. The better-aimed defendant, the scholars argue, is the party that actually put the work online, not the one that pointed to it, and contributory and vicarious liability already exist to reach those who facilitate infringement without directly causing it.
For now, my practical advice has not changed since 2022. Because a copyright plaintiff can often choose where to sue, and because the trial courts outside the Ninth Circuit are increasingly hostile to the server test, the only safe assumption is that embedding can expose you to a display-right claim, wherever you are. The Supreme Court has already passed on the question once, denying review in McGucken. Congress, which wrote the current Copyright Act in 1976 and has amended it many times since, has not touched the display right to account for a technology that did not exist then.
So it falls to the Fifth Circuit. Its decision in Emmerich will be the first appellate ruling on the server test from outside the Ninth Circuit. Affirm, and the appellate consensus holds while the pressure for Supreme Court review keeps building. Reverse, and there is finally a genuine circuit split, the one I flagged as the trigger for Supreme Court review back in 2022, and the question of who displays an embedded image becomes very hard for the Justices to keep avoiding.
Stay tuned.

by Lee Gesmer | Apr 27, 2026 | General
Lee Gesmer and Andrew Updegrove
In 2023, we wrote about the D.C. Circuit’s decision in American Society for Testing and Materials v. Public.Resource.Org (ASTM II), which held that a nonprofit organization’s free online publication of technical standards incorporated by reference (IBR) into law constituted copyright fair use. We expressed concern that the decision underestimated the threat to the delicate symbiotic relationship between standards development organizations (SDOs) and the governments that rely on their work, and we called for a legislative solution. Since then, the legal landscape has shifted further, and not in the SDOs’ favor. A new court decision and pending federal legislation have brought this issue to a head, and we think it’s time for an update.
The central issue that we discussed in 2023, and that remains unresolved today, is this: private standards development organizations invest enormous resources creating a broad range of technical standards, such as building, safety, and electrical codes, that federal, state, and local governments routinely incorporate into law by reference. The traditional SDOs that are most likely to develop such standards usually fund their work largely through the sale and licensing of their standards. When a government body incorporates a standard into law by reference – IBR – the public gains a legitimate interest in reading the law it is required to obey, but the SDO retains a legitimate interest in the copyright that sustains its operations. The question courts have struggled with is whether the act of incorporation by reference, and the public’s right of access to the law, overrides that copyright protection. As we discuss below, courts have increasingly answered that question in ways that threaten the financial foundations of the organizations whose work we all depend on.
The Case Law
The courts have addressed this issue in a series of decisions that have moved consistently, and for SDOs, alarmingly, in one direction. In 2020, the Supreme Court held in Georgia v. Public.Resource.Org that government officials who “speak with the force of law” cannot claim copyright in works created in their official capacities, though the Court left open the broader question of privately-developed standards incorporated by reference.
The D.C. Circuit addressed the issue in ASTM I (2018), remanding for further consideration of fair use. In ASTM II (2023) the court held, on a fact-specific record, that a nonprofit’s manner of providing access to incorporated standards constituted fair use. We were critical of ASTM II when it was decided, noting that the court had underestimated the economic consequences for SDOs and flagging the risk that the reasoning would not remain confined to nonprofit actors. That risk has now materialized.
In April 2026, the Third Circuit decided American Society for Testing and Materials v. UpCodes, Inc., extending the fair use reasoning of ASTM II to a for-profit commercial platform. Taken together, these decisions have created a body of case law that leaves SDO copyrights in incorporated standards increasingly difficult to enforce, even against commercial actors.
Crucial to these cases is the legal doctrine of “fair use,” which provides that certain uses can be made of copyrighted works without the consent of the copyright owner.
The UpCodes case is notable for two reasons: first, in applying the standard four-factor fair use test, the Third Circuit held that UpCodes’ use was “transformative” despite the fact that it reproduced the standards without alteration, reasoning that UpCodes’ purpose – disseminating the law – was fundamentally different from ASTM’s purpose of advancing industry best practices. Second, the court was not convinced that the SDO had suffered material economic harm, while acknowledging the substantial public benefit of free access to the law.
The practical takeaway is significant: after UpCodes a for-profit company may be able to publish incorporated standards online, build a commercial business around them, and still prevail against a copyright infringement claim on fair use grounds.
An important caveat: the UpCodes decision is not a final judgment on the merits. It arose in the context of ASTM’s motion for a preliminary injunction, which required the court to assess only whether ASTM was likely to succeed at trial, a lower and more provisional threshold than a final merits determination. The court itself acknowledged that the record was incomplete, particularly on the critical question of market harm, noting that key facts – including what percentage of ASTM’s revenue derives specifically from incorporated standards, and how many ASTM subscribers have canceled in response to UpCodes’ free publication – remain undeveloped. The parties will have the opportunity to return to court and litigate these questions on a fuller factual record. It is possible, though far from certain, that a more complete record on market harm could shift the fourth factor in ASTM’s favor. For now, however, the preliminary injunction ruling leaves UpCodes free to continue publishing ASTM’s incorporated standards, and sends an unmistakable signal to other commercial actors that the fair use argument is very much available to them.
The Pro Codes Legislation
Against this backdrop, many SDOs have been urging Congress to provide a legislative solution. The Pro Codes Act – formally titled the Protecting and Enhancing Public Access to Codes Act – has been introduced in both the House (H.R. 4072) and the Senate (S. 4145), with bipartisan support in both chambers. The bill addresses the problem by conditioning copyright retention on a straightforward quid pro quo: SDOs that make their incorporated standards freely available online – in a searchable, accessible format, at no cost to the user – retain full copyright protection in those standards, notwithstanding their incorporation into law.
We supported an earlier version of this legislation when we wrote in 2023, and we continue to support it. The public reading room approach it codifies is sensible, fair, and already reflects what many responsible SDOs have voluntarily put in place. However, the bill has a significant gap that, in our view, must be addressed before it can accomplish its central purpose. The bill amends Title 17 of the United States Code – the Copyright Act – by adding a new section confirming that incorporated standards retain copyright protection if the SDO meets the posting requirements. What it does not do is address the fair use defense under Section 107 of the Copyright Act. That omission, we believe, may prove fatal to the bill’s effectiveness.
The UpCodes decision, following closely after ASTM II, confirms that the courts are not going to solve this problem in the SDOs’ favor. Two circuits have now addressed IBR-related copying, and the fair use defense has prevailed each time. The Pro Codes Act is a necessary and welcome step, and we hope Congress moves quickly to enact it. But as currently drafted, the bill leaves the fair use door wide open. A defendant copying an incorporated standard can concede that the SDO’s copyright is valid, and then may still prevail based on fair use, as UpCodes did.
To close that gap, the bill needs express language providing that where an SDO has complied with the public posting requirements, the fair use doctrine shall not constitute a defense to infringement based on copying in connection with incorporation by reference. Such a limitation would raise important policy and potentially constitutional questions, but without it, the statute risks being largely ineffective
The stakes are high: the voluntary consensus standards system has served the public extraordinarily well for more than a century, producing essential safety and technical standards at no cost to taxpayers. Preserving the financial model that sustains it, while ensuring genuine public access to the law, is a goal worth getting right.

by Lee Gesmer | Mar 30, 2026 | DMCA/CDA
This post is the third in a series following Sony Music Entertainment v. Cox Communications through the courts. In May 2024 I wrote about the Fourth Circuit’s decision, which reversed a $1 billion jury verdict against Cox on vicarious liability grounds while affirming a finding of contributory infringement, and sent the case back for a new trial on damages. Last November, when the Supreme Court agreed to hear Cox’s appeal, I warned that the stakes extended far beyond the parties themselves. On March 25, 2026, the Supreme Court brought the saga to a close, reversing the contributory infringement ruling and handing Cox a complete victory. But the real story here isn’t the billion dollars, or even Cox’s vindication. It’s what this decision does to the Digital Millennium Copyright Act (the “DMCA”).
Writing for a 7-2 majority, Justice Thomas held that an internet service provider (“ISP”) does not commit contributory copyright infringement merely by continuing to provide internet access to subscribers it knows have been identified as repeat infringers. The Court’s ruling rests on a straightforward principle: contributory liability requires either that the provider induced infringement through affirmative acts, or that it offered a service tailored to infringement – one incapable of substantial non-infringing use. Cox did neither. It sold broadband internet access, a service with countless lawful uses, and it never encouraged its customers to pirate music. That, said the Court, is the end of the matter. And in reaching that conclusion, the Supreme Court may have given every online service provider a reason to ask a very uncomfortable question: why bother complying with the DMCA at all?
To understand why this decision carries such sweeping implications, you need to understand how Cox ended up outside the DMCA’s safe harbor in the first place. As I explained in my earlier posts, the DMCA provides ISPs with powerful protection against secondary copyright liability. However, that protection comes with conditions. To qualify, a provider must adopt and reasonably implement a policy that terminates subscribers who are repeat infringers. This is not a technicality. It is the cornerstone of the bargain Congress struck in 1998: providers are granted a safe harbor if – and only if – they take meaningful steps to address chronic infringers on their networks.
Cox blew that bargain. In an earlier case, BMG Rights Management v. Cox (4th Cir. 2018), the Fourth Circuit found that Cox had a repeat infringer policy on paper but didn’t enforce it. Internal emails showed that Cox employees routinely reinstated known infringers rather than terminating them, prioritizing subscription revenue over copyright compliance. That finding disqualified Cox from DMCA safe harbor protection for the entire period covered by the Sony lawsuit. As a result, the Sony case was litigated entirely outside the DMCA framework, under the older judge-made doctrines of contributory and vicarious infringement. And it is precisely because Cox was stripped of DMCA protection – and still won – that this decision poses such a profound threat to the statute Congress carefully crafted almost three decades ago.
Which brings us to the uncomfortable question this decision raises for the entire online copyright enforcement regime. The DMCA is, at its core, a takedown statute. It was designed around a carefully constructed system of incentives and obligations: providers must adopt and implement repeat infringer policies, respond expeditiously to takedown notices, and act on “red flag” knowledge – that is, cases where infringement is obvious even without a formal notice. Comply with those requirements and you earn safe harbor protection. Ignore them, as Cox did, and you face secondary liability. That was the stick that was supposed to keep providers in line. The Supreme Court has just knocked it out of copyright holders’ hands.
After Sony v. Cox, the calculus has fundamentally changed – not just for the repeat infringer requirement, but for the entire DMCA compliance regime. Consider what this decision actually means in practice. A provider that ignores takedown notices faces no contributory liability, as long as it isn’t actively promoting infringement. A provider with clear “red flag” knowledge of specific infringing content – the court-made doctrine developed in cases like Capitol Records v. Vimeo – can apparently look the other way without consequence.
In a concurring opinion Justice Sotomayor makes exactly this point: after the majority’s decision, ISPs “no longer face any realistic probability of secondary liability for copyright infringement, regardless of whether they take steps to address infringement on their networks and regardless of what they know about their users’ activity.” She went further, noting that Cox’s own counsel conceded at oral argument that under the majority’s rule the DMCA safe harbor provision would not “do anything at all” going forward. That is a remarkable admission – and a remarkable thing for a Supreme Court decision to leave standing without serious engagement from the majority. Sotomayor’s conclusion is worth sitting with: Congress enacted the DMCA safe harbor as part of a carefully balanced incentive structure, premised on the assumption that providers faced real exposure if they didn’t comply. The majority, she wrote, has consigned that structure to obsolescence.
The irony of Sony v. Cox is that it was Cox’s own bad behavior – its cynical, revenue-driven failure to implement a meaningful repeat infringer policy – that put the case outside the DMCA framework and forced the Court to confront the outer limits of common law secondary liability. Had Cox simply complied with the statute, the case would never have raised these questions. But the Supreme Court, in ruling for Cox on the broadest possible grounds, has handed every online provider a roadmap that leads to the same destination without any of the effort: don’t induce infringement, don’t tailor your service to it, and you are free to ignore takedown notices, red flag knowledge, and repeat infringer policies alike. Justice Sotomayor is right that Congress did not enact the DMCA just so the Supreme Court could eviscerate it. But eviscerate it the Court has – and unless Congress acts to restore the incentive structure it so carefully built in 1998, the question in this post’s title – why bother with the DMCA? – will increasingly answer itself.
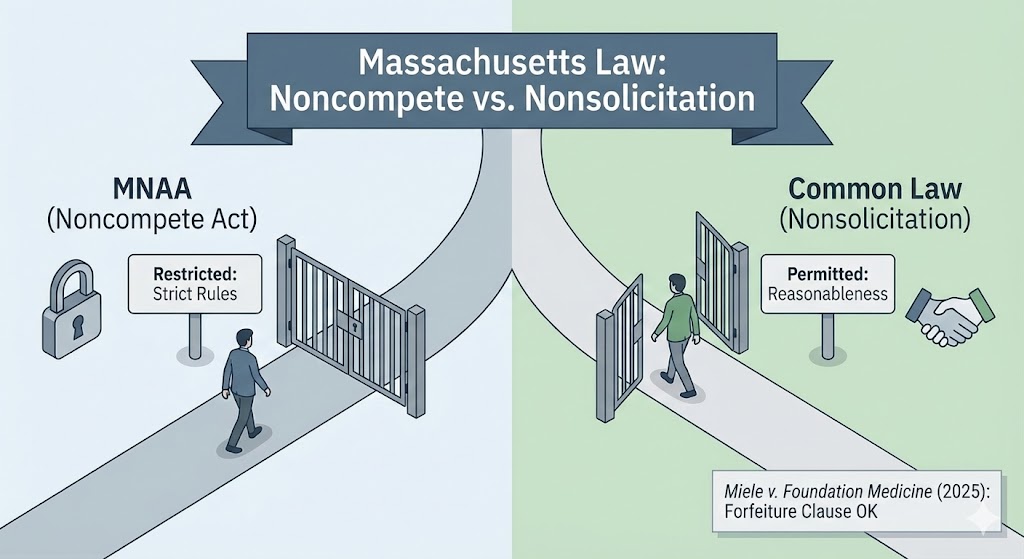
by Lee Gesmer | Dec 7, 2025 | Employment
When the Massachusetts Noncompetition Agreement Act (MNAA) took effect in October 2018, I described the law in detail and wrote that employers and employees were entering “a new era” in noncompete law. The statute imposed formalities, created new employee protections, and limited the enforceable duration of noncompetes. But it also drew a set of carefully worded exclusions – most notably for nonsolicitation agreements. I predicted that those exclusions would become critical as employers adjusted to this new law.
Seven years later, the Supreme Judicial Court has now decided its first significant case interpreting the statute, Miele v. Foundation Medicine, Inc. (2025). The decision answers a narrow question, but it carries substantial practical consequences. The court held that the MNAA does not apply when an employer conditions severance pay on compliance with an employee-nonsolicitation covenant. In other words, adding a forfeiture-of-benefits clause to a nonsolicit does not convert it into a noncompetition agreement.
What the MNAA Regulates – And What It Doesn’t
The MNAA regulates agreements that bar a former employee from engaging in post-employment competition. To be enforceable, such agreements must satisfy a gauntlet of statutory onerous requirements: advance notice, a written agreement signed by both parties, the right to consult counsel, a one-year limit on duration (with narrow exceptions), and “garden leave” or other agreed-upon consideration.
And, importantly, the MNAA includes “forfeiture for competition” agreements under the definition of noncompetition agreements. This was designed to prevent employers from avoiding the statute’s requirements by replacing a noncompete with a compensation-forfeiture clause that accomplishes the same result. In other words, employers should not be able to sidestep limits on noncompetes by changing the mechanism of enforcement.
The statute is sufficiently burdensome that employee noncompete agreements, once a routine feature of employment contracts in Massachusetts, are now seldom used.
But the statute does not sweep in every type of restrictive covenant. Its definition of “noncompetition agreement” excludes several categories, including:
- Employee and customer nonsolicitation covenants
- Confidentiality and intellectual-property assignment provisions
- Covenants linked to the sale of a business
As I noted in 2018, those exclusions matter. A well-drafted nonsolicitation clause can serve much of the protective function that noncompetes historically played. The MNAA left those covenants to be governed by common-law reasonableness standards rather than the statute’s rigid framework.
The Dispute in Miele
Susan Miele signed an employee-nonsolicitation agreement when she joined Foundation Medicine in 2017. When she left the company in 2020, she entered into a “transition agreement” providing substantial severance benefits. That agreement incorporated the earlier nonsolicitation covenant and added a forfeiture clause: if she breached any of her continuing obligations, she would forfeit unpaid benefits and repay benefits already received.
After Miele joined a competitor, Foundation Medicine alleged that she solicited several FMI employees during the one-year restricted period. The company stopped payments and demanded repayment. Miele sued, arguing that the forfeiture provision was an unenforceable “forfeiture for competition” agreement subject to the MNAA.
She took this argument all the way to the Massachusetts Supreme Judicial Court and lost.
The SJC’s Holding: A Nonsolicitation Clause Remains a Nonsolicitation Clause
The SJC’s analysis turned on the statute’s definitions. The MNAA:
- Excludes nonsolicitation agreements from the category of noncompetition agreements; and
- Defines forfeiture-for-competition agreements as a type of noncompetition agreement.
Given those two premises, the court held that a forfeiture triggered by a breach of a nonsolicitation covenant is not a “forfeiture for competition agreement” under the MNAA. The forbidden conduct was solicitation, not competition itself. Because the underlying covenant falls outside the statute, the forfeiture remedy does not bring it back within the statute’s scope.
In short: the presence of a forfeiture provision does not change the legal identity of the underlying restrictive covenant. If the covenant is a nonsolicitation clause, the MNAA does not apply.
Implications Going Forward
Miele gives employers and employees much-needed clarity, and it confirms several practical realities about the MNAA:
- Nonsolicitation provisions remain outside the statute, even when backed by serious financial consequences. A severance agreement that conditions payment on compliance with a nonsolicitation covenant does not trigger the MNAA merely because the remedy is forfeiture or repayment. These provisions will continue to be governed by pre-2018 common law.
- The MNAA’s reach depends on the nature of the restricted activity, not the chosen remedy. If an agreement penalizes an employee for working for a competitor, it is a forfeiture-for-competition agreement subject to the statute. If it penalizes solicitation, it is not. The drafting focus rests on the conduct being restricted, not the mechanism of enforcement.
- Common-law reasonableness remains the governing framework for nonsolicitation covenants. Duration, scope, legitimate business interest, and employee role still matter. Parties should expect future litigation over what counts as “solicitation,” a concept the common law has never cleanly defined. I wrote about this perplexing topic more than ten years ago in Nudge, Nudge, Wink, Wink – Are You “Soliciting” in Violation of an Employee Non-Solicitation Agreement?
- Separate statutes still matter. Miele does not insulate forfeiture clauses from scrutiny under the Massachusetts Wage Act or other employment statutes. Severance structured as earned compensation, for example, may present Wage Act issues if subject to forfeiture.
- Expect heavier reliance on nonsolicitation + severance-forfeiture structures. The decision validates a drafting strategy employers began adopting after 2018: use narrower covenants that avoid the MNAA altogether, coupled with meaningful financial incentives for compliance.
Conclusion
When the MNAA was enacted, the open question was how far courts would go in applying its protective rules beyond traditional noncompetes. Miele provides a clear boundary: the MNAA governs restraints on competitive employment, not every restrictive covenant that may influence post-employment behavior. Nonsolicitation clauses, even with substantial economic consequences attached, remain on the common-law side of the line.
Employers will undoubtedly make fuller use of that space. Employees and their counsel will scrutinize whether a provision labeled “nonsolicitation” is in substance a broader restriction. And the statute will continue to generate interpretive questions as parties test its edges.

by Lee Gesmer | Nov 11, 2025 | Copyright, DMCA/CDA
Update: On March 26, 2026 the Supreme Court decided this case in favor of Cox. The Court held that an internet service provider would be liable for infringing content posted by a third party only when it induced users’ infringement or provided a service “tailored to infringement.”
****************
Can your internet provider be held liable for what you download? That’s the question the Supreme Court will wrestle with on December 1, when it hears Sony Music Entertainment v. Cox Communications – a case that could reshape how the internet handles copyright enforcement.
Back in May 2024 I wrote about the Fourth Circuit’s February 2024 decision in this case, breaking down the court’s divergent rulings on vicarious and contributory liability. Now the stakes have gotten even higher. The Supreme Court has agreed to hear Cox’s appeal, and the case has attracted an unusual ally: the U.S. Solicitor General, whose brief warns that the Fourth Circuit’s approach threatens universal internet access.
The Case in Brief
Cox Communications is one of the largest ISPs in the United States. Sony and other record labels sent Cox hundreds of thousands of infringement notices identifying subscribers who used peer-to-peer networks to trade copyrighted songs. The labels argued Cox knew certain customers were serial infringers but failed to disconnect them, preferring to keep collecting subscription fees. A jury agreed and awarded a record $1 billion in damages.
The Fourth Circuit split the verdict. It reversed the finding of vicarious liability, holding that Cox’s flat-fee model meant it earned the same revenue whether subscribers infringed or not – therefore Cox received no “direct financial benefit” from infringement. But it affirmed contributory liability, finding that Cox knew specific subscribers were repeat infringers and continued providing them internet service, which materially contributed to the infringement.
Because the jury’s award didn’t distinguish between the two theories, the court vacated the entire damages and remanded for a new trial on contributory infringement alone. Cox appealed this decision to the Supreme Court.
What’s Before the Supreme Court
Cox argues the Fourth Circuit fundamentally misread copyright law. The company points to the Supreme Court decisions in Sony v. Universal (the 1984 “Betamax case”) and MGM v. Grokster (2005), both holding that secondary liability requires intentional encouragement or inducement of infringement – not mere knowledge that a service could be misused. Cox’s central theme can be summarized as: “We sell internet access, not infringement.”
Importantly, the U.S. Solicitor General agrees with Cox. The government warned that the Fourth Circuit’s rule cannot be reconciled with precedent and would threaten universal internet access. If ISPs face liability simply for knowing users might infringe again, they’ll over-enforce – cutting off schools, libraries, and households based on unverified accusations.
Sony sees it differently. The labels argue Cox wasn’t a neutral conduit but made a calculated business decision: it received hundreds of thousands of specific notices yet chose to keep subscribers connected to preserve revenue. This isn’t passive knowledge – it’s complicity. They also point to Cox’s allegedly ineffective repeat infringer policy, which Sony claims was designed to retain revenue rather than stop infringement.
Why Didn’t the DMCA Control This Case?
Normally, Internet providers like Cox are protected by the Digital Millennium Copyright Act (DMCA), which gives online services a “safe harbor” from liability for their users’ infringement. To qualify, an ISP must adopt and reasonably enforce a repeat infringer policy – in other words, it has to disconnect customers who repeatedly violate copyright law after proper notice.
Cox, however, lost that protection years ago. In an earlier case the Fourth Circuit found that Cox had a policy on paper but didn’t actually enforce it. Internal emails showed that employees routinely reinstated known infringers to keep their monthly payments coming. That decision disqualified Cox from the DMCA’s safe harbor for the period covered in the Sony lawsuit. BMG Rights Management v. Cox (2018).
As a result, this case proceeded outside the DMCA framework, under the older, judge-made rules of secondary copyright liability – the doctrines of contributory and vicarious infringement. The Supreme Court is now being asked to decide how far those doctrines can reach when the statutory safe harbor no longer applies.
However, both sides know that if the Court sees Sony v. Cox as a one-off “Cox-was-a-bad-actor” case, the Court may decide it narrowly, or dismiss the broader policy concerns. The parties have worked hard to frame the case as not an edge case, arguing that there is industry-wide noncompliance with the safe harbor and that the case has cross-industry implications far beyond Cox.
What’s Next
The Court hears arguments on December 1, with a decision expected by June 2026.
If the Court accepts Sony’s theory – that an ISP can be contributorily liable simply for continuing to provide internet access to a subscriber after receiving infringement notices – the decision would push secondary liability far beyond the Sony/Grokster framework. Cox warns that this effectively creates a “two-notices-and-terminate” rule, forcing ISPs to cut off entire households, dorms, hospitals, and even downstream networks based on a small number of unverified accusations. Cox argues that this approach conflicts with Grokster which requires intentional, affirmative conduct to support liability; merely supplying multi-use communications infrastructure to the public on uniform terms, it argues, cannot be a culpable act.
A ruling for Sony would reverberate beyond broadband. Cloud hosts, campus networks, content delivery networks (such as Cloudflare and Akamai), and payment processors – all of whom receive automated copyright notices – would feel pressure to over-terminate users to avoid the inference that they “purposefully” facilitated infringement. The DMCA’s safe-harbor regime, which contemplates reasonable repeat-infringer policies, would become secondary to a broader judge-made duty to disconnect first and ask questions later. In that scenario, copyright enforcement would move deeper into the internet’s basic plumbing, reshaping how infrastructure providers manage risk and potentially constraining access for lawful users across entire networks.